Pourquoi choisir ELK pour mettre en avant ses données ?

Un système d’information comporte une multitude de données toutes différentes les unes des autres. L’intérêt est de les utiliser et de les traiter pour pouvoir les analyser de façon simple et efficace. Pour cela, l’utilisation d’outils de traitement de données, de recherche et d’analyse comme ELK, sont nécessaires. YPSI utilise ces outils dans ses offres de performance et supervision.
Qu’est-ce-que ELK ?
L’abréviation ELK signifie Elasticsearch Logstash Kibana. Ces outils font partie de la suite Elastic tout comme FileBeat.
- Elasticsearch est un moteur de recherche et d’analyse qui centralise le stockage des données.
- Kibana est l’interface graphique d’Elasticsearch, qui nous permet de faire différents types de visualisation et de tableaux de données.
- Logstash est un outil de traitement de données brutes. Il ingère des données provenant d’une multitude de sources (équipements réseaux, applications), les transforme et les envoie vers un système de stockage.
- FileBeat est un agent de transfert léger qui permet de centraliser les logs et les fichiers.
Ces applications sont généralement associées pour le traitement de données, et elles sont conçues pour répondre à de multiples cas d’utilisation.
Comment fonctionne ELK ?
FileBeat / Logstash
FileBeat est équipé de modules pour les sources de données afin de simplifier la collecte, l’analyse et la visualisation des formats de logs. Il utilise aussi un protocole de régulation de flux lorsqu’il envoie beaucoup de données vers logstash ou Elasticsearch.
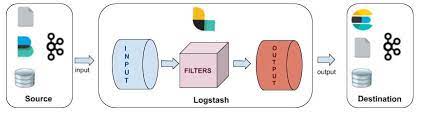
Logstash utilise un système d’entrée, filtre et sortie. Les plugins d’entrée et de sortie sont obligatoires alors que le filtre est facultatif. Le plugin d’entrée ingère tout type de données comme du syslog, des applications web, du stockage, des services cloud, etc. Le système de filtre à différents objectifs :
- Transformer des données non structurées en données structurées
- Déchiffrer des coordonnées géographiques d’un adresse IP
- Exclure entièrement des champs confidentiels
- Faciliter le traitement, quelle que soit la source, le format ou le schéma des données
Fonctionnement Logstash
Elasticsearch / Kibana
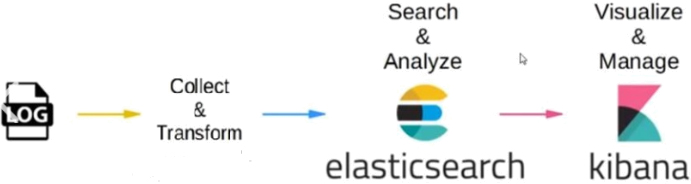
Elasticsearch est capable de traiter des données numériques, textuelles, géographiques, structurées, non structurées, etc. Il utilise le port 9200 pour recevoir ces données. Ensuite, il nous suffit de catégoriser les données via des index pour pouvoir faire de la recherche et de l’analyse. Il peut être utilisé en simple nœud ou en cluster de nœud. Le plus souvent, il est utilisé en cluster pour bénéficier d’une haute disponibilité.
Kibana est l’interface qui vous permet de visualiser les données Elasticsearch. Vous pourrez donc créer des visualisations ainsi que des tableaux de bord, pour exploiter au mieux les données et avoir une meilleure analyse. Il vous offre aussi la possibilité d’organiser et de sécuriser vos données, grâce au Kibana Spaces et ses contrôles d’accès basés sur les rôles. Vous pourrez donc inviter des utilisateurs dans certains espaces et gérer leurs accès aux différents contenus et fonctionnalités.
Fonctionnement Elasticsearch / Kibana
Cloud Search Service by Flexible Engine
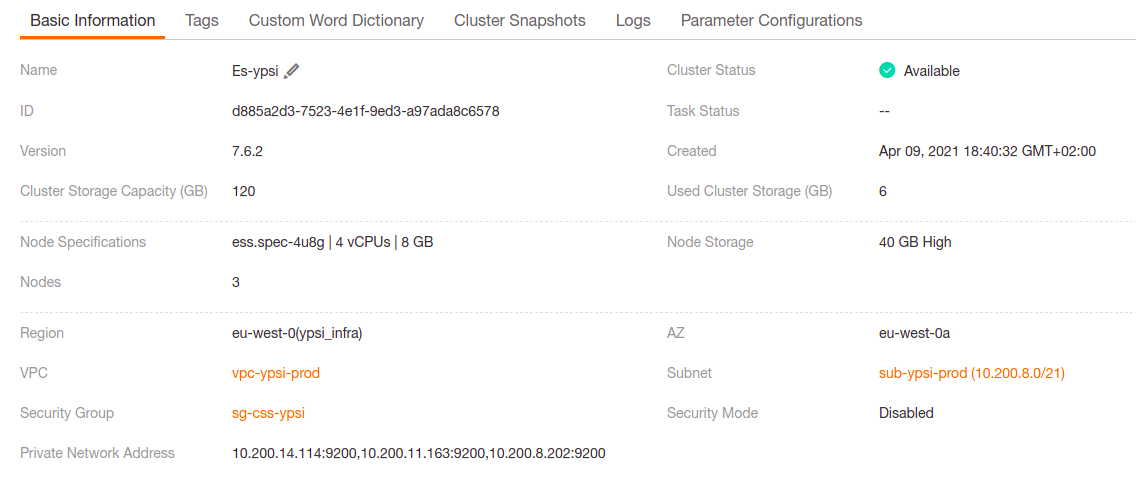
Cloud Search Service (CSS) est un service du cloud d’Orange (Flexible Engine) qui intègre la solution Open Distro. Open Distro est une version openSource d’ELK développée par AWS. CSS gère Elasticsearch et Kibana. Vous avez la possibilité de créer un cluster d’un ou de plusieurs nœuds pour Elasticsearch. Kibana est automatiquement installé en même temps qu’Elasticsearch. La notion de sécurité est aussi disponible.
Interface de configuration Cloud Search Service
Comment YPSI s’en sert pour ses clients ?
Notre objectif pour nos clients est d’utiliser leurs données pour les mettre en avant, afin de leur faciliter les recherches et les analyses. Prenons l’exemple d’une configuration pour des données syslogs en provenance de points d’accès Wifi de type Cisco Meraki.
On commence par créer le fichier de configuration pour syslog en fonction du type de données :
input { udp { port => 514 type => syslog } }
Note : La plateforme Cisco Meraki doit être configurée pour envoyer ses logs vers l’ip du serveur logstash.
filter { if [type]=="syslog" { grok { match => [ "message", "<[0-9]*>[0-9]* %{NUMBER:id} %{USERNAME:station} %{WORD:log-type} src=%{HOSTPORT:ip-source} dst=%{HOSTPORT:ip-destination} mac=%{MAC:adresse-mac} [agent=']*%{DATA:navigateur}?'? request: %{WORD:methode} %{URI:url}" ] match => [ "message", "<[0-9]*>[0-9]* %{NUMBER:id} %{USERNAME:station} %{WORD:log-type} src=%{HOSTPORT:ip-source} dst=%{HOSTPORT:ip-destination} mac=%{MAC:adresse-mac} request: %{WORD:methode} %{URI:url}" ] } } }
output {
elasticsearch {
hosts => ["https://x.x.x.x:9200"]
index => "syslog-%{+YYYY.MM.dd}"
cacert => "/etc/logstash/conf.d/es.cer"
user => "xxxxx"
password => "xxxxxxxxxxxxxxxxxxx"
ssl => true
ilm_enabled => false
ssl_certificate_verification => false
}
}
Dans cette configuration, la connexion SSL vers Elasticsearch est active. Par défaut, cette option est désactivée, mais elle est conseillée et dépend de la configuration de votre cluster elasticsearch.
Les données sont filtrées via l’outil GROK qui structure vos données non structurées. Cela nous permet de faire des visualisations plus précises, en fonction des informations importantes à retenir et d’avoir des tableaux de bords de qualité.
Exemple de tableau de bord syslog
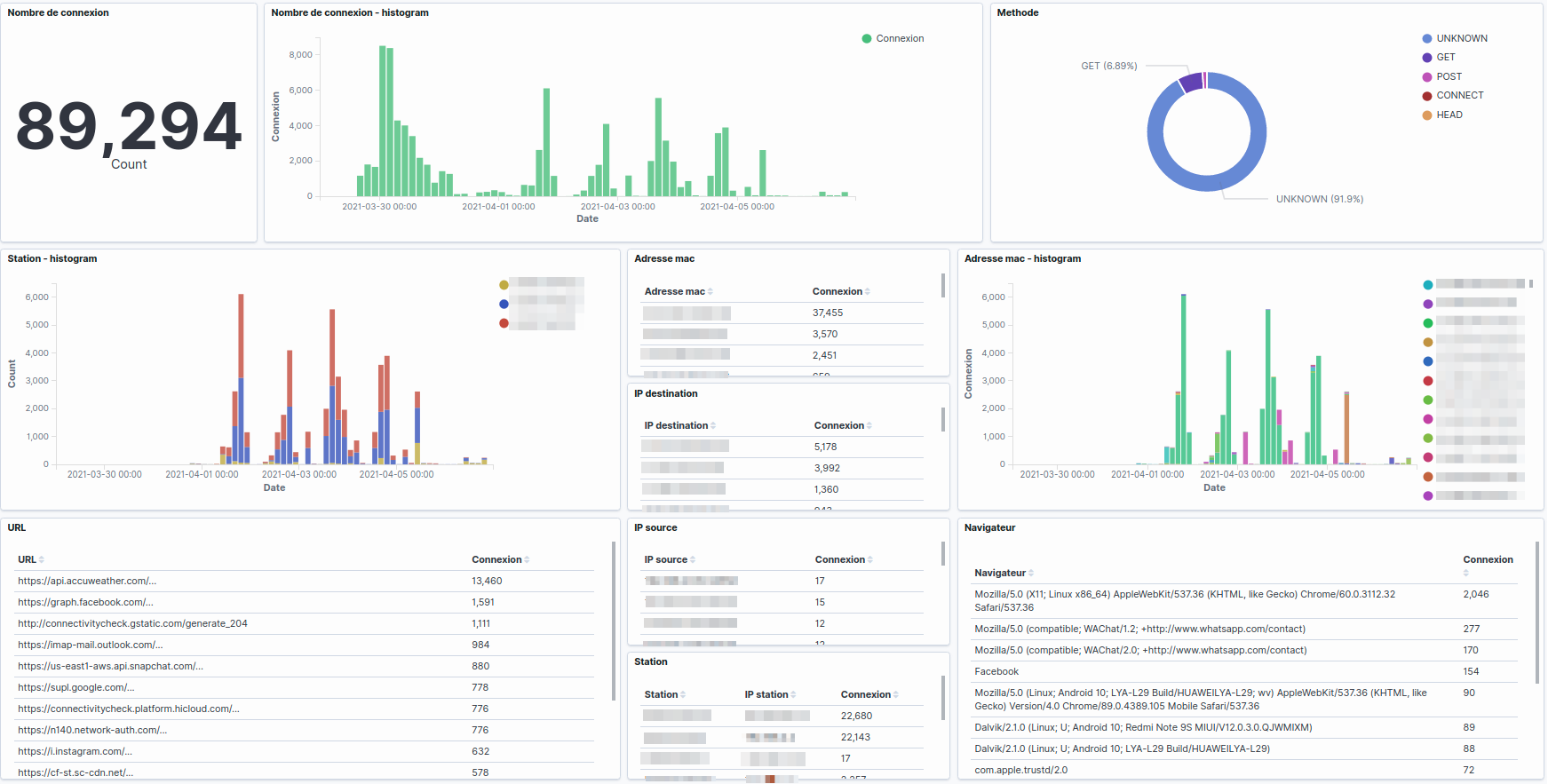
Dans ce tableau, on peut voir plusieurs types de visualisation (tableau de données, histogramme, metric, diagramme circulaire). Chaque visualisation permet de mettre en avant des données précises comme
- metric = nombre de connexions
- histogramme = répartition des connexions
- tableau de données = information de connexion
- diagramme circulaire = méthode de la requête URL
Ces tableaux de bord ont plusieurs utilités :
- Analyser les logs
- Rechercher des informations
- Faire des rapports de suivis
Les avantages et inconvénients
Avantages
- Rapidité / Fluidité
- Haute disponibilité en cluster
- Évolutif vers l'Application Performance Management (APM)
Inconvénients
- Fonctionnalités payantes (export pdf,...)
- Pas de Tableaux de bord prédéfinis prêts à l’emploi
- Coût supplémentaire pour avoir un stockage conséquent pour conserver la donnée
YPSI met à votre disposition un accompagnement personnalisé dans la mise en avant de vos données, en fonction de vos besoins et objectifs. N’hésitez pas à nous contacter afin d’en discuter.
Partagez cet article :